
I have been fascinated by our progress in autonomous agents and systems recently. With success in self-driving cars, similar use cases in business are already being developed. Self-governing systems that can self-maintain, self-heal, self-learn, and self-improve are becoming a reality. We do not have to wait for entirely independent operations, and we can contribute to the engineering and ethics behind making them commercial.
Here is one way. But let’s step back a little.
Analytics and Recommender Systems
To derive insights from what happened in the past, we rely on descriptive analytics. To understand what might happen in the future, we depend on predictive analytics. To get guidance on what should be done, we use prescriptive analytics. Traditional prescriptive recommender systems use optimizations, math, and rules-based systems to calculate a statistical confidence rating for generated prescriptive recommendations. Since modern prescriptive analytics uses black-box deep learning, simulative analytics is used for explaining, inferring and identifying best outcomes from generated prescriptive recommendations.
Descriptive analytics
Descriptive analysis helps describes historical information making it understandable. Insights like counts, sums, averages, distributions, deltas, etc. are summarized and compared over periods of time. Humans infer all insights from tabular and graphical representations of data and take actions accordingly.
“The system trained 12,000 labeled examples per second in the previous iteration”.
Predictive analytics
Predictive analysis helps plan the future by predicting and forecasting outcomes. Data-driven and probabilistic predictions are based on technologies ranging from simple trendlines to advanced data mining, statistical data modeling, rules-based algorithms, traditional machine learning, and representation-learned deep learning. The accuracy of ML and DL predictions improves with data completeness, consistency, unambiguity, correctness, and the ability to accurately fill missing data values with informed guesses. Actions may be taken based on the confidence level of predictions.
“The system might be able to train 14,000 labeled examples per second in the next iteration.”
Prescriptive analytics
Prescriptive analysis recommend and explain actions, i.e., the ‘why?‘. Prescriptive analytics solutions use historical and transactional data combining it with business rules, machine learning, deep learning, optimizers, and simulations to arrive at recommendations and supporting explanations.
“The system might be able to train 14,000 labeled examples per second next iteration because i/o times have consistently improved.”
Prescriptive analytics are best implemented as recommender systems.
Prescriptive recommender systems
In general, recommender systems are matchmaking algorithms between products, services, APIs or customers (accepting customers may be users, enterprises, bots, self-driving cars, other autonomous systems). An e-commerce company recommends products to its customers. A pet adoption service matches pets to humans. Job-applicants are recommended open jobs and candidates are recommended to companies in need of talent. A weather reporting API may be matched with an automated consumer of such a service. Meetups and events may be recommended for people interested in Artificial Intelligence.
Recommender systems thrive in environments where it is expensive and hard to match between millions of entities with discrete attributes and experiences. Systems fully aware of such attributes and past experiences utilize segmentation techniques like demographic, geographic, technographic, psychographic, behavioral, attitudinal, etc. for recommendations. Common recommender systems are collaborative filtering, content-based filtering, knowledge-based, and hybrid.
- Content-based filtering algorithms recommend entities that are similar to those that the user has rated in the past, has stored in wishlists, or is considering currently. Content-based filtering has the cold-start or unknown user problem.
- Collaborative filtering is predicting interests of a user based on interests of similar people. Collaborative filtering, however, does not work well with too much (scale), too little data (sparseness [Ref 1]), and because every user is different. Clustering users in a group and treating all of them collectively is not one-on-one experience.
- Knowledge-based recommender systems rely on attributes of entities (e.g., users and products) being matched. They are best used when collaborative filtering or content-based filtering cannot be used, e.g., in cold-start or new user use cases. They do have the standard knowledge-acquisition bottleneck, but you always know something about every user, e.g., technographic and geographic attributes.
Simulative analytics
Besides understanding why an action should be taken, we also want to understand its consequences if the recommended action was taken. We do so by reproducing actions and outcomes in a simulative analysis environment. Simulated analysis provide ‘what-if?‘ analysis, or in terms of recommendations, the implications of a recommendation. Digital simulations and other AI inferability or explainability techniques help in interpreting possible outcomes if recommendations are acted upon.
Simulative environments in the context of prescriptive recommendations are virtualized environments used to test both a user’s what-if analysis and a system generated recommendation.
“If this should happen, it is recommended that standby servers be reduced by at most 7%. Reducing standby servers by 7.2% would cause an insignificant impact on training speeds given the ability to train 14,000 labeled examples.”
Autonomous agents and autonomous operations
Recommender systems, when used in analytics, suggest actions to improve the system. In advanced analytics systems, each recommendation may be accompanied by a dynamically generated dashboard to assist the operator, but decisions are still made manually.
The problem is recommendations can be overwhelming to operators and may get dated before an operator has a chance to review and act on them. Dynamic dashboards may be generated for each recommendation to help the operator but the operator is still responsible for all decision making.
Recommendations can be overwhelming to operators.
Similar to how a number of A|B testing use cases is being replaced with Artificial Intelligence systems and specifically Reinforcement Learning [Ref 3], recommender systems need to become prescriptive and automated, and eventually autonomous for specific use cases.
Prescriptive Recommender Systems that learn and work with operators is a good start. The system can first offer prescriptive recommendations and learn what types of recommendations the operator is approving and then automate those actions.
“You approved similar recommendations 6 of 7 times. Approve automatically in the future?”
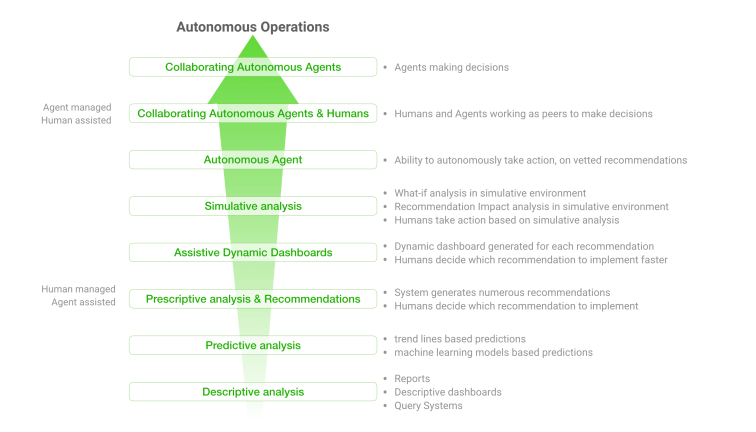
Autonomous Agents
Prescriptive Recommender Systems take us a step closer to autonomous operations made possible by multiple collaborating autonomous agents. Agents that have the capability of making decisions either as a peer to humans or as a manager are autonomous agents. They refer to entities that can makes their own choices about how to decide and act in its environment.
Intelligent Autonomous Agents
Historically, autonomous agents have differed from intelligent autonomous agents, but I am assuming intelligence. Advancements in reinforcement learning, imitation learning, and transfer learning have made autonomous agents cable of making decisions while being knowledgeable of representation of the user’s goals and desires.
Autonomous Operations
If you google autonomous operations or similar terms, you will come across business units that have full P&L autonomy under a General Manager, military UAVs or drones that can return to base once they can no longer communicate or accept commands from the base, or decentralized autonomous organizations that are fundamentally code and smart contracts on a blockchain that may run in the future without management or people.
Autonomous operations in this context are similar to autonomous vehicles or self-driving cars [Ref 2]. Initially, they can be self-sufficient in specific regards and require human help in other scenarios.
Autonomous operations is a collaboration between multiple autonomous agents and humans, with varying levels of cooperation from humans across the spectrum.
Initial verticals for autonomous operations include Security, DevOps, DevSecOps, application performance management, analytics, lifecycle management, etc. Running a Cassandra repair job based on an intelligent alert as opposed to a cron job is a simple example. Viv, generating sequenced scripts for use of multiple stackable services for richer and complex queries, is another example. Program synthesis , i.e. finding a program that satisfies the user intent derived from a specification, is another example how automation is being achieved.
Autonomous Businesses and Corporations
Fully Autonomous Businesses
Eventually, we may see what Gartner calls “Fully Autonomous Businesses,” i.e., systems that “set their own goals and operate in a truly autonomous manner.”
AiPoly.com or poly.ai is an example of a fully automated commerce store that uses image recognition and object detection in image sequence streams. Amazon Go was also in the news few months ago when they announced a checkout-free grocery store.
Distributed Autonomous Corporations
McKinsey also wrote about “Distributed Autonomous Corporations” as “self-motivating, self-contained agents, formed as corporations, will be able to carry out set objectives autonomously, without any direct human supervision. Some DACs will certainly become self-programming.”
Endnotes
- The sparseness and scalability issues in collaborative filtering systems have been solved by the alternating-least-squares with weighted-λ-regularization (ALS-WR) algorithm “Large-scale Parallel collaborative filtering for the Netflix Prize.”
Source: The Growing Ubiquity of Personalization - Autonomous cars and perception. Source: Visual Perception, in Humans, Animals, Machines, and Autonomous Vehicles
- 20+ years of A|B Testing: Bucket Testing to Reinforcement Learning
- Recommender systems, reference
- Gartner reference
- McKinsey Distributed Autonomous Corporations
- Gartner: Fully Autonomous Businesses
- See Edge- and cloud analytics endnote below
Edge- and cloud-analytics
To improve the responsiveness of analysis and actions, we perform edge-processing of data where applicable. The data collected on a device or platform maybe partially processed on edge before sending it to the cloud in real-time or in digest format for further analysis, categorization, aggregation, summarization, and organization. The edge-analysis helps improve responsiveness and experiences in certain use cases but may be expensive or impracticable on different device types. Autonomous cars, smartphones, and IoT sensors use varying level of edge-analysis and processing.
